

 转寄
转寄作者 王道维 2018.02.25
20世纪以前,科学技术主要是用来解决人类生存问题,改善生活品质的工具。但是20世纪中叶以后,人类许多生存与社会问题却反而来自科学技术的扩张。当2016年围棋程式AlphaGo甚至击败人类冠军时,人工智慧(Artificial Intelligence)终于公然踏入人类最深层的思想领域[1],且快速地应用在工商、金融、交通、治安、文化、教育、军事等等几乎所有领域,带领出第四次工业革命[2]来改变人类现今生活的面貌。唯一不能确定的是,这场改变的极限会在哪里?为机器赋予「智慧」或许最终只是科幻小说中的情节,但是我们却可能更高估了自己。在各国政府与企业带头推广AI相关的研究与产业之际,最不能遗忘的恐怕是AI所带来关于人类意义与价值的挑战。
一、问题的核心:
顾名思义,「人工智慧」是用人为设计来模拟出可堪比人类智慧(或智能)的机器。但是人们对于「智慧」该如何定义,本身就不见得有一致性的标准[3]。与其困扰于如何定义适当的字汇,上个世纪中数学家图灵(Alan M. Turing)就提出了一种相当精简但含意深刻的评估方式,至今仍广为流传。图灵建议可以藉由测试某机器是否能表现出与人等价且无法区分的谈话内容(限文字沟通),来确认它是否具有「智慧」,也就是着名的「图灵测试」。不过任何思虑严谨的人马上会发现,这个测试其实相当模糊,因为牵涉到要与甚么样的人对谈?要谈那些范围?要谈多久才算?等等细节。因此这种测试方式在讲求实务与精确的科技浪潮中,更多只是一种象徵性的意义。
但是图灵测试本身的核心意义,是笔者认为过往在思考AI相关影响时最重要却最常被忽略的观点:重点不在于「本质」是否相同,而是「果效」是否等价,并且藉由语言沟通的即时性效果来绕过对于心智的恒常性定义[4]。也就是说真正的问题恐怕不是「AI何时可以超越人类?」或是「AI会不会拥有自我意识?」,而是应该反过来问,「人类还有多少AI无法达到的智能?」或者「人类何时会接受AI为情感的对象?」。有许多理由相信,后者出现的可能性与影响范围恐怕还远高于前者,更值得政府部门与有识之士的关注,也正是本文的核心主旨。
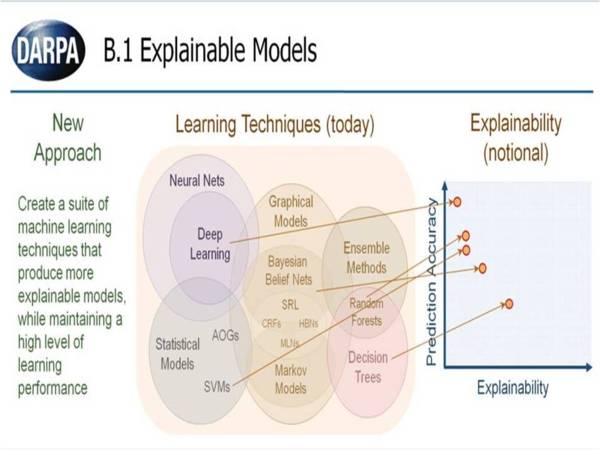
图一:美国国防高等研究计划署(Defense Advanced Research Projects Agency,DARPA)于2016年公开徵求关于可解释性AI的计画说明投影片(摘自可公开使用的版本),说明不同类型的AI在预测的准确性(Prediction Accuracy)与可解释性(Explainability)上不同的分布。目前应用上准确率最高的Deap Learning却也是可解释性最低的技术。相关资料可见于https://www.darpa.mil/program/explainable-artificial-intelligence
二、深度学习的特色
其实早从20世纪中第一代的电脑开始,与神经网路有关的人工智慧研究就已浮现,但50多年来经历许多技术与数据上的瓶颈,甚至几度停滞不前[5]。最近第三波人工智慧应用的大爆发其实得力于许多机缘的结合,包括计算更为快速的处理器与累积在网路上大量的资料。其中的核心技术乃是藉由所谓「深度学习」(Deep Learning)[6]来实现许多以前无法企及的应用(特别是在图形辨识与竞赛游戏方面)[7],笔者认为这次深度学习的成功在许多方面展现出图灵测试的核心意义,以至于对人类自我的认知或价值感带来深刻的影响,包括高准确率、自我学习与无解释性:
1.高准确率(High Accuracy):
「准确率」一直是计算工程所追求的目标之一,所需要的不仅是硬体设备的先进程度,更需要有好的软体(如计算法,algorithm)的开发。过往电脑的基本运算速度虽然早已完全超越人类,但基本上都是需要程式设计师将想要完成的工作化为一行行以数值运算为基础的程式语言来让电脑执行。但是如果要实践真正的人工智慧,显然电脑要有能力回应人类生活中更多无法结构化、数值化或程式化的动作,这也是过往人工智慧最大的挑战。
举例来说,三岁小孩都可以轻易根据照片分辨猫与狗,但这对于电脑而言这却是非常困难的,因为我们就算将所有种类的猫狗数据(例如形状、颜色、大小等)输入电脑,还要考虑猫狗也会又坐又趴或被修剪外型,根本难以完全定义。以「全球视觉辨识大赛(ILSVRC)」为例,2012 年以前所有的人工智慧所达到最高的辨识率只有70-75%,但是2012年由加拿大多伦多大学的辛顿(Geoffrey Hinton)所带领的团队使用深度学习瞬间将准确度提升至85%,后来甚至可达99%以上而超越人类的眼睛,促使这一波AI应用的大爆发。事实上这样精确的图形辨识能力也已经用在治安维护与失踪儿童搜寻等,甚至可以比专业医生还准确地辨识医学影像找出初期肿瘤。而大家所熟知的AlphaGo也是建立在这种深度学习的架构来判读棋盘的局势。
这种透过深度学习所得到的高准确率(见图一,与其他方式的比较)对于掌握人类复杂的意识或非意识行为带来突破性的可能,代表我们过往直线性的知识建构方式不但有其极限,也很可能正是人工智慧未来通过图灵测试的重要方向,因为人类大脑中对于视觉或其他神经讯息的判读很可能正是采用类似的模式。
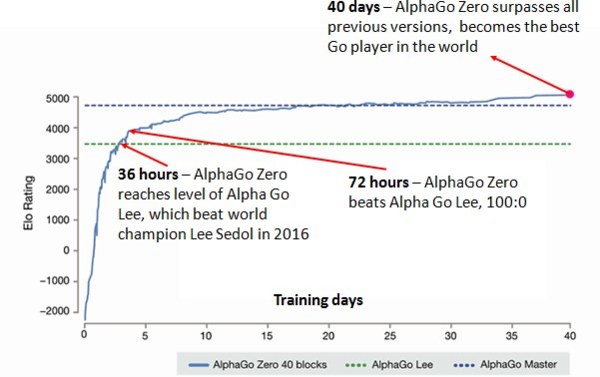
图二:AlphaGo Zero 自我学习的曲线:从完全没下过围棋开始,只花了3天(自我对战450万次)就赢过2016年战胜李世石的版本,到第21天后就战胜曾经赢过柯洁的版本,40天后赢过所有其他过去的人类或程式。资料来源:https://www.kdnuggets.com/2017/10/alphago-zero-biggest-ai-advance.html
2.自我学习(Self-Learning):
机器学习(Machine Learning)本身并非新的概念,因为只要藉由适当的程式设计,机器或电脑本来就不难从人类所规定的判断标准中学习调整内在参数,将运作的效率极大化。但是机器的「自我学习」则是完全不一样的事情,因为它要可以不透过人类工程师所灌输的知识而自行从所得到的资料中寻找彼此间的关系,产生有价值的「知识」,也就是所谓的非监督式学习(unsupervised learning)。这种「自我学习」也意味着具有此人工智慧的机器可能会找到一些「目前所有人类都尚未了解或认知到的知识内容」,因而与传统电脑搜寻或被动性的机器学习有天壤之别。
举例来说,2017年Google发表的AlphaGo Zero版本,可以在只输入围棋基本规则而没有学习任何人类的棋谱下,从与自己比赛的随机乱下开始,只花了21天就将棋力提升甚至赢过曾经战胜世界排名第一柯洁的旧版本[8],成为有史以来最强的围棋程式(见图二)。研究者在这中间发现AlphaGo Zero可自行摸索出许多人类目前已经熟知的下棋规则,但更包含其他从未曾被棋手研发出的下法,后来反而成为许多职业棋手的学习对象。
从生物学的角度,这种自行从看似散乱无章的资料中寻找出规律的行为其实与生命体可以从外界散乱的能量转换为有机化合物的过程相当类似,可以视为一种减少乱度(Entropy)的自我组织(Self-organization)的行为。也就是说,自我学习的人工智慧的确已经在某种程度上掌握到生命若干重要特色,问题只是在于我们许可它做哪些事情。
3.无解释性(Non-Explainability):
既然深度学习可以有高准确率与自我学习的特性,是否就能协助解决人类重要的问题呢?答案是还不太行,原因是深度学习其实是以一种有效率的参数调控方式来模拟所输入的资料,进而「预测」出未来有类似但不完全相同的情形下应该如何行动。不过由于输入学习的资料通常都非常庞大,几乎所有的参数都是内在自动调控而非外在干预的结果(因为不知道那些参数是作甚么用),使得即使是写出这程式的电脑工程师也无法预知最后的反应结果,也就是无解释性[9]。
举例来说,打败世界冠军李世石或世界棋王柯洁的Alpha Go版本,是以人类现有的围棋棋谱作为学习对象,其围棋实力几乎等同于古往今来所有围棋大师的总和(但是仍输给AlphaGo Zero)。但这并不代表设计者或任何的棋手能够了解它下每步棋的原因。这种「无解释性」也正是深度学习的特色与挑战(见图一),因此可能成为我们应用人工智慧时的阴影。例如史丹福大学于2017所发表的人脸辨识系统[10],藉由交友网站上读取数万个异性恋与同性恋者的脸孔来训练,后来分辨同性恋者照片的准确率竟然可达到90%以上!这当然已经不是设计者或任何人能够理解的范围,而是代表一种全新的知识可能透过AI来带给人类。但是如果深度学习无法提供足够好的解释能力,这样的「知识」又该如何被正确的评价或使用呢?所带来的影响与困扰也将显而易见。
三、真正的挑战:认识自己[11]
目前台面上所讨论到关于人工智慧对于人类的影响,除了「AI是否会比人类聪明?」这类八卦问题外,最有意义的是关于工作机会渐少的问题。毕竟AI的应用一定会让许多白领工作(包括医生与律师)被取代。但是如同人类过往三次的工业革命,日后总会有新的工作机会出现,只是各国政府在这转型期间需要有更多的配套来协助因此失业者,并且要极力避免贫富差距的再扩大,只是这个议题并非本文的重点。
如文章开头所述,图灵测试的精随就在以一种去本质化的方式来定义人工智慧,这使得人类与机器的界线变得相对模糊。而这一波基于深度学习的人工智慧发展的确与过往不同(如前所述),可能会反映出更多人类自身的问题。这又可以从几个方面来看:
1. 情感与人性的软弱:
过往的三次工业革命的确带给我们许多丰富的物质生活,但是也的确证明了当一个工具方便便宜到一个地步,就会大量普及而成为「必需品」,让我们本来的能力开始弱化甚至被取代(多久没有拿笔写字了?J)。在人工智慧结合物联网与机器人的第四次工业革命浪潮中,我们会因为逐渐习惯让机器代替我们作一些本来只有人才能作的决定,因而对它演化出一种特殊的情感依赖关系。从神经科学来说,这是因为我们的镜像神经元(Mirror Neuron)能将其他动物或物品的外在行为(如AI机器人的回应)在大脑中产生对应的活化,进而启动各种主观的情绪反应。也就是说,即使理智上使用者知道对象只是一台机器而非人类,也可能因为紧密的生活依赖而产生类似移情(transference)的作用,发生情感上的连结。

图三:全方位的聊天机器人微软小冰与网友的对话截图。从2014年5月上线以来,目前与小冰对话过的人数已超过一亿人。小冰可由网友的回应来不断学习掌握情感表达的方式,现在几乎可以用与真人无异的方式来活泼的回应,读者可以自己去试试看。资料来源:http://big5.xinhuanet.com/gate/big5/www.xinhuanet.com/tech/2017-11/02/c_1121892818.htm
事实上,对于有若干智能或社交障碍的孩子或独居老人而言,AI机器人是个非常安全来学习对话与交友方式的工具。毕竟对这些在人际关系中不易得到支持的边缘人而言,可以自我学习的AI机器人将会演化成一个个特别的「个体」而成为难以被他人所取代的「朋友」。而近年在美国卖得火红的亚马逊智慧音箱Alexa就是因为与使用者可以透过自然语言的对话与服务而成为许多家庭的一分子。微软(Microsoft)在大陆发展的聊天机器人小冰每天甚至与至少1500万人聊天,成为许多宅男夜晚倾诉谈话的对象(见图三)。毕竟,追一个女友又要花钱花时间还可能要忍受她闹脾气,还不如与这位聪慧有趣又温柔不会拒绝的AI女友谈心聊天?当然,聊天机器人的功能远不只如此,与谘商理论搭配,有的甚至可以当作心理谘商的一种方式(例如Woebot)或约会顾问,全年无休。
因此,即使目前的AI应用还在中低度人性化的阶段,只要越来越普遍与方便的使用在生活许多层面,使用者就会因为AI有效的自我学习功能而发生情感转移的效应,最终会习惯将之当成某种真实的人物而难以分离。
2. 操纵与偏见的幽灵:
与真实的人类不同,人工智慧近期跳跃式的发展倚赖于社群媒体并网路中所累积的大数据资料,因为这些数据正是训练AI深度学习到高效能的关键。但是能掌握这些资料的公司或政府运作必然是不透明的(因为要保护个资),因此就产生严重资讯不对等的情形:例如全球活跃用户已超过二十亿的Google搜寻引擎与社群网路Facebook,可以从其用户的使用资料中每天搜集与其生活习惯有关的资讯,用来评估对其最合适的广告或新闻资料来投放。对使用者来说这无疑是更为便利贴心的服务,但可能更代表一种细腻而难以挣脱的资讯操纵。何况这些资料也难以为其他企业所完全掌握,间接形成资讯垄断而破坏自由市场竞争的公平性(见图四)。

图四:六家着名科技公司组成的「AI伙伴」,目标是发展对人类生活有助益的人工智慧。但即便有此目标,未来遇到市场竞争或领导人理念改变的时候,又有谁可以对他们使用这些大数据或AI技术有所监督?但是另一个在AI发展上几乎同等重要的国家是中国,夹着近年经济快速发展与极高的数据量(上网人口众多)的优势,已经是另一个主导性的力量。但政治权力非常极中稳固的中国政府又会如何使用这些技术,将是另一个无法忽视的隐忧。
当然,可能更显而易见的问题是,在若干政府权力比较集中的国家,政府亦可透过大数据与人工智慧对于人民的各类型资料(例如脸部照片)有更完整的搜集,透过各地的摄影机来捕捉重大刑案的嫌疑犯或搜寻失踪人口(已有许多实际的案例)。但是显然这也可以成为对付政治犯或异议份子的方式,或者更轻易制造假新闻来混淆舆论方向。
最后,即使整个大数据的使用权限完全公开(假设没有隐私的问题),或至少数据的管理者没有刻意误导,但是这些依据一般人使用习惯所建立起来的资料库也必定同时夹杂着许多关于人性、种族、性别、年龄、外表、文化等等的偏见与刻板印象(讲好听一点,就是文化习惯),同样也会在机器学习的过程中被AI吸收,甚至进而被强化[12]:因为如果人工智慧藉这些有偏见的资料所作的回应不被另外区分(也可能很难区分)而回流于网路中,很可能就会重覆被以后的AI使用而形成递回放大的结果,让偏见更为加深而难以再复原(并且带着人工「智慧」之名)。毕竟如果人类自己的价值观都是混乱的,又如何期待AI能扮演上帝的角色?这也是为何笔者认为在人工智慧技术与应用面蓬勃发展的时候,一定需要更多投入人文相关的研究。
3. 意义与价值的失落:
在许多关于人工智慧所带来的影响讨论中,一个主流的看法是认为人类的文学或艺术创新是最难被取代的(如李开复的看法5)。虽然这部分的确因为人性的复杂度与文化的多元性而尚未有如同AlphaGo这般革命性意义的突破,但相关的努力其实从未因此停滞(谁知道哪天不会出现一首完全由AI创作的歌曲得到葛莱美奖?)。毕竟即使目前AI还未能单独创作出「好的艺术作品」,但「平凡的作品」一样可能会得到大众接受,因此而大大降低人类对于艺术创作的重视程度。
但这个问题并不是如同「又多一种工作被AI取代」那样简单,因为艺术创作通常被视为人类精神文明最高的成就之一[13],是一种超越理性却又似乎捕捉到某种真实的经验,一种与利益无关的自由心智活动,彷佛上帝创世而为人间带来新的善美内涵。倘若文学艺术的创作也可能透过某种人工智慧来模仿,似乎也间接地暗示人文主义所高举的人性价值其实并未比机器高明多少?那时人类自我存在的意义又与机器有何差别?例如当有一天家中失火了,我们真的愿意只救那顽固难相处的老头,还是去救那已经学习许多特殊知识且善体人意的AI机器人?[14]
关于「人类存在的意义」这个千古纠缠不清的主题,笔者认为哈佛大学生物社会学家威尔森(Edward O. Wilson),在其书中的分类可作为一种参考[15]。他将意义分为「外在关系性」与「内在目的性」的层次。人工智慧的出现无疑大大增加前者对人类意义的解释,但是同时却似乎削弱后者的内涵,除非我们可以接受「AI是为人类而造」来类推「人类亦是为上帝而存在」的这种宗教性的类比[16]。而这部分(内在目的性)的答案,显然只能是人文学科(包括宗教学、哲学、艺术与人类学等)来回应的主题。
四、结语:
人工智慧近年来的发展与未来的广泛应用已经是无法改变的事实,也的确引起各国政府的注意与企业/学术界的积极参与。除了专业的技术层面以外,过往在大众媒体中大部分的讨论都会过度夸大AI的功能而落入另类的科幻八卦。
但是本文希望藉由聚焦于「深度学习」上的几个重要特质来反思我们自己真实的处境:面对AI,我们对人类自身的认识其实并没有如此足够的把握。以上的讨论或许可以用深度学习中常见的多层神经网路(Multi-layer Neuron Network)来将深度学习的三个特质与人性软弱的三个面向来连结(如图五),或许可以帮助读者更清楚之间的关系。
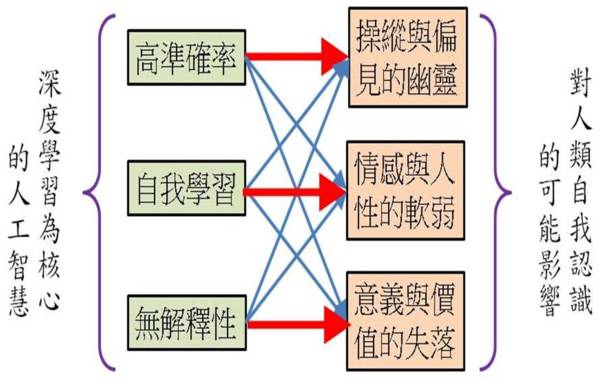
图五:藉由深度学习常用的多层神经网路来表达深度学习所带来的第三次人工智慧对人类自我认识的可能影响。红色较粗的箭头代表权重较大的直接影响,而蓝色较细的箭头代表权重较轻的间接影响。
至于回应这样挑战的方式,笔者绝非认为要因噎废食地停止或反对AI相关的发展。事实上正好相反,笔者认为应该更多仿效特斯拉与spaceX创办人马斯克(Elon Musk)建立非营利组织Open AI的精神,不但应该要在技术面积极投入人工智慧的研究,并且要做得比那些只是为了商业利益或当权力者更好,才能有机会将AI的优点转化成更多社会大众可以分享到的资源,避免资讯、技术与利益的独占。但同时间,积极推动AI研究的政府或企业更要在相关的人文与社会科学当面投入更多的研究资源,不但帮助社会早日适应AI世代的到来,预备好前瞻性的法律规章来避免过度滥用,也更要更多回去探索那些古老的哲学、道德与历史的议题。或许这方面不像物质科学一般容易有明确的标准答案,但是过去一个多世纪来急速激荡的科技浪潮的确冲昏了我们,让许多人迷失于科技的成就却遗忘了自己生命的意义与价值感。毕竟只有当我们更认识自己是谁,活在世上的意义与目的以后,在未来有更多眼花撩乱的AI应用时才有可能比较不会迷失,反而更有把握面对这些科技创新,使之成为人类的祝福而非咒诅。
(完)
**作者为国立清华大学物理系教授、谘商中心主任、国家理论科学研究中心副主任
**全文(不含附注)发表于2/24/2018风传媒专栏评论:http://www.storm.mg/article/401682
附注:
[1] 在人工智慧的发展历史上,1997年IBM深蓝(Deep Blue)战胜西洋棋世界冠军卡斯巴罗夫亦是重要的里程碑。但电脑围棋的困难度公认远胜于西洋棋(因为规则更简单却变化更多),在2016年以前甚至未达职业一段的棋力。相较之下AlphaGo是一种架构于模拟大脑神经网路的深度学习程式,藉由模态辨认(Pattern recognition)直接从过往高手的棋谱盘面来学习最重要的评估函数(Evaluation function),如同人类的学习过程(只是更加快速),因而较深蓝更接近人类判断思考的模式。
[2] 第一次工业革命源自18世纪末蒸汽机的发明,是人类首次使用机械力取代自然动力来从事生产;第二次工业革命是19世纪末由电动机与内燃机的发明所带动,配合许多新材料的发现并炼钢技术的突破而大量制造各种生活与交通工具;第三次工业革命是20世纪中由资讯科技所领导的数位化浪潮,使人类生活各层面都离不开电脑与网路的资讯;第四次工业革命咸认为已开始于本世纪初,由人工智慧、物联网、机器人与生物科技所综合实现的全方位自动化生活,将人类的身体(甚至意念)和外在机器协调合一。
[3] 由于中文的「智慧」带有更多道德性与哲思性的意涵,更接近英文的Wisdom。因此笔者同意Intelligence若翻译成「智能」可能更为准确,但这并会不影响本文所有的讨论。
[4] 通常我们会将这种通过图灵测试的通用人工智慧称作「强AI」(Strong AI),而在那之前,我们已经有更多「弱AI」(Weak AI)是在某些特定功能上已超过人类的智能(例如脸孔辨识或竞赛游戏等)。
[5] 与AI相关的介绍书籍有许多。对一般大众而言,或许李开复与王咏刚合着的《人工智慧来了》(天下文化,2017)对相关发展与应用有较为全面与持平的介绍。
[6] 所谓的「深度学习」是指模仿大脑神经的网路结构,将神经元(简单的计算单位)建构成一层或多层的神经网路来彼此连结。连结的权重反映出是神经元间突触的连接程度,是一组可调控的参数。训练时先藉由大量的资料与已知的结果来「学习」,让程式自动调整优化这些权重参数,后来便可以藉这组训练完成的神经网路来对其他新资料进行的辨识或预测。这样的想法过往也有被提出,只是过去的演算法无法在3-4层网路之后还能提高准确率。新型的演算法可应用于多层神经网路并依然保存高准确率。
[7] 如同图一所显示,人工智慧可以有很多类型或不同的演算法,并非只有深度学习。在处理不同类型的数据或目标时当然还有许多更精致的方式来决定其学习的果效,于此就不再详述。例如IBM华生电脑主要就是针对分析人类的自然语言而设计,不但可以听得懂益智竞赛(Jeopardy)中拐弯抹脚的人类语言而击败冠军,还能阅读医学论文与分析病人各种资料而找到有针对性的医疗方式。这就不需要大数据来学习,也可能更适用于某些特殊问题的处理。
[8] 关于AlphaGo Zero的介绍可见各处的网路新闻或者官方网页:https://deepmind.com/blog/alphago-zero-learning-scratch/
[9] 当然,目前已经有一些程式可以协助将若干特徵标示出来以协助使用者「理解」深度学习所给出的答案。但是这只是由程式自己所给出的资料而非解释,仍需要人类事后的介入来完成。所以对于已经超过人类目前所理解的知识结构的问题,深度学习是无法给出有效解释的。
[10] 人类目测的准确度对男同志的正确率只有61%,女同志54%。但这套软体辨识同一人的5张照片,正确辨别男同志和女同志的比率分别是91%和83%。相关报导可见,https://udn.com/news/story/6812/2690868
[11]相传是刻在古希腊阿波罗神庙的三句箴言之一,有人认为源自苏格拉底。
[12]《大数据的偏见》,麦尔荀伯格(V. Mayer=Schonberger)与库机耶(K. Cukier)着,天下文化2012。
[13] 例如我们可以从人本主义心理学家马斯洛人类需求的层次理论(Maslow's Hierarchy of Needs)来看,分别是生理需求、安全需求、社会需求、尊重需求、自我实现需求和晚年所补充的超自我实现需求六类。其中艺术创作的高峰状态是被归类于超自我实现中。
[14] 顺道一提,个性化人工智慧(Project PAI)已经出现,可以利用区块链与AI结合的技术将一个人的外型、语言与各种资讯保密存储存,并创造出一个彷佛原来使用者的影像与说话方式来扮演各类型虚拟身分。详情可见https://projectpai.com/
[15]《人类存在的意义:一个生学家的思索》(威尔森(Edward O. Wilson)着,如果出版社)。威尔森认为意义同时包含着内在与外在两个意涵,包括内在的目的,让我们知道为何会如此这般,还有外在的「关系」,让我们了解与其他的事物如何有关。
[16] 类比(analogy,或译为「类推」)是通过比较两个相似的论述,将已知事物的特点推衍到另一方,但所比较的两者不一定有实质上的关系。与逻辑演绎不同,其规范的有效性仍受限于其表意目标所需的准确度,但仍为科学或哲学在论述不可见事物时常用的方法。例如科学家常以太阳系的行星运动来类比电子绕原子核的运动,虽然这样的图像类比是不准确的(甚至违反物理定律的)。在文学上通常是以「比喻」的描述性(而非推理式)的方式呈现。
很优秀却不快乐?
传承是一点一滴
似苦而乐、似乐而苦
 站内文章搜寻
站内文章搜寻